개요
이번 포스팅과 다음 포스팅까지 서울시에서 제공하는 서울 확진자 현황 데이터를 크롤링하고, EDA(Exploratory Data Analysis)를 수행하여 다양한 인사이트를 발견하는 내용에 관하여 작성하려고 합니다. 모든 진행 절차는 YouTube today오늘코드 채널에서 사용한 방식을 기반으로 하며, 최신 데이터를 사용하기 위해 데이터 범위를 2021년 2월 1일까지 확장하여 수집 및 분석을 수행하였습니다.
특별히, 이번 포스팅은 서울시 코로나 발생동향 웹사이트에서 서울 확진자 현황 데이터를 크롤링하는 과정을 정리했습니다.
참고한 자료는 아래와 같습니다.
본문
서울시 코로나 발생동향 웹사이트에 접속해서 하단을 보면, 아래와 같이 현재 날짜(2021.02.02) 0시를 기준으로 서울 확진자 현황을 알 수 있는 2개의 테이블을 확인할 수 있습니다. 이중에 아래에 있는 "연번", "환자", "확진일", "거주지", "여행력", "접촉력", "퇴원현황" 7개 칼럼으로 구성된 테이블 데이터를 크롤링할 것이며, 다음과 같은 특징을 가지고 있습니다.
- 확진자 현황 데이터는 '10001번 ~ 현재' 및 '1번 ~ 10000번' 탭으로 분리되어 있고, 각 탭은 다시 여러개의 페이지(1, 2, 3, ...)로 분리되어 데이터를 웹사이트에 출력합니다.
- 최종 크롤링할 데이터의 범위는 최초 서울시 코로나 환자 발생 시점부터 가장 최근 코로나 환자 발생 시점까지 입니다.
- 즉, '1번 ~ 10000번' 탭에 존재하는 전체 페이지 데이터 + '10001번 ~ 현재' 탭에 존재하는 전체 페이지 데이터를 크롤링하는 것이 목적입니다!

필요한 라이브러리
최초 파이썬 pandas, numpy 라이브러리를 import 합니다.
import pandas as pd
import numpy as np
데이터를 크롤링 할 서울시 코로나 발생동향 웹사이트 URL 주소를 Pandas read_html()에 입력하면, 해당 웹사이트에서 table 태그를 가지고 있는 테이블 데이터를 반환합니다.
- 총 6개의 테이블을 반환합니다.
url = "https://www.seoul.go.kr/coronaV/coronaStatus.do"
table = pd.read_html(url)
len(table)
하지만, 필요한 서울 확진자 현황 데이터는 가져오지 못하고 단지 칼럼명만 가져오는 것을 확인할 수 있습니다.
df = table[3]
df.head()
원래 코로나 초기만 하더라도 환자수가 지금보다 적었기 때문에 서울 확진자 현황 데이터를 웹사이트 한 개 페이지에 모두 출력할 수 있었지만, 시간이 흐를수록 환자수가 증가하여 여러 개 페이지(1, 2, 3, ...)로 나눠서 출력하는 방식으로 변경되었습니다. 즉, pd.read_html()만으로는 최초 코로나 환자 발생 시점부터 최근 데이터까지 모두 크롤링할 수 없습니다.

이를 위해 pd.read_html()은 칼럼명을 가져오는 용도로만 사용하고, 실제로 필요한 데이터 크롤링은 파이썬 requests 라이브러리를 사용합니다.
- requests
- 작은 브라우저로, 웹사이트를 읽어오기 위한 목적을 가지고 있습니다.
- 웹사이트의 이미지, 텍스트, 표 등의 데이터를 요청(Request)하여 원하는 데이터를 반환(Response) 받을 수 있습니다.
import requests
최초 웹사이트 1페이지 데이터 요청(Requst)
먼저 간단하게 1개 페이지 데이터만 요청하고, 반환 받는 절차를 확인해보겠습니다.
최초 1페이지 서울 확진자 현황 데이터 URL 주소는 아래 절차에 따라 확인할 수 있습니다.
- 서울 확진자 현황 테이블 아무 데이터에 마우스를 위치한 후에 우클릭
- 검사 선택
- Network 탭 선택
- XHR 선택
- get_status_ajax.php?draw=1... 선택
- Headers 탭 선택
- Request URL 확인

확인한 Request URL을 복사하여 보기 쉽게 분해하여 f-string 문자열로 연결하고, 상태를 확인합니다.
- 정상: Response [200]
url = "https://news.seoul.go.kr/api/27/getCorona19Status/get_status_ajax.php?draw=1"
url = f"{url}&columns%5B0%5D%5Bdata%5D=0&columns%5B0%5D%5Bname%5D=&columns%5B0%5D%5Bsearchable%5D=true&columns%5B0%5D%5Borderable%5D=true&columns%5B0%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B0%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B1%5D%5Bdata%5D=1&columns%5B1%5D%5Bname%5D=&columns%5B1%5D%5Bsearchable%5D=true&columns%5B1%5D%5Borderable%5D=true&columns%5B1%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B1%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B2%5D%5Bdata%5D=2&columns%5B2%5D%5Bname%5D=&columns%5B2%5D%5Bsearchable%5D=true&columns%5B2%5D%5Borderable%5D=true&columns%5B2%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B2%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B3%5D%5Bdata%5D=3&columns%5B3%5D%5Bname%5D=&columns%5B3%5D%5Bsearchable%5D=true&columns%5B3%5D%5Borderable%5D=true&columns%5B3%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B3%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B4%5D%5Bdata%5D=4&columns%5B4%5D%5Bname%5D=&columns%5B4%5D%5Bsearchable%5D=true&columns%5B4%5D%5Borderable%5D=true&columns%5B4%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B4%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B5%5D%5Bdata%5D=5&columns%5B5%5D%5Bname%5D=&columns%5B5%5D%5Bsearchable%5D=true&columns%5B5%5D%5Borderable%5D=true&columns%5B5%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B5%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B6%5D%5Bdata%5D=6&columns%5B6%5D%5Bname%5D=&columns%5B6%5D%5Bsearchable%5D=true&columns%5B6%5D%5Borderable%5D=true&columns%5B6%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B6%5D%5Bsearch%5D%5Bregex%5D=false&order%5B0%5D%5Bcolumn%5D=0&order%5B0%5D%5Bdir%5D=desc"
url = f"{url}&start=0&length=100&search%5Bvalue%5D=&search%5Bregex%5D=true&_=1612249942210"
response = requests.get(url)
response
최초 1페이지 서울 확진자 현황 데이터를 예시로 .json 형태로 확인해보면, draw, recordsTotal, data 등을 key로 가지고 있음을 확인할 수 있습니다.
- draw: 페이지를 출력한 총 횟수(?) -> 여러 개로 나눠진 페이지 번호를 무작위로 선택할 때마다 +1 증가
- recordsTotal: 전체 페이지에 존재하는 데이터 개수
- data: 선택한 페이지에 저장된 데이터 -> 서울 확진자 현황 데이터는 한 개 페이지에 100개 row 데이터를 가지고 있으므로, data는 100개 데이터를 가지고 있음
data_json = response.json()
data_json
다만, 위에서 지정한 Request URL이 모두 필요하지 않고, draw, start, length 정보만 있어도 웹사이트에게 데이터를 요청할 수 있습니다.
- draw: 페이지를 출력한 총 횟수(?) -> 여러개로 나눠진 페이지 번호를 무작위로 선택할때마다 +1 증가
- start: 한 개 페이지의 가장 첫 번째 데이터 인덱스
- (ex) 한 개 페이지 데이터가 10개씩 있다면, 1페이지 start=0, 2페이지 start=10, 3페이지 start=20, ...
- length: 한 개 페이지의 데이터 사이즈
아래 Request URL은 최초 웹사이트 1페이지의 테이블이 100개의 데이터를 가지고 있음을 알 수 있습니다.
url = "https://news.seoul.go.kr/api/27/getCorona19Status/get_status_ajax.php?draw=1"
url = url + "&order%5B0%5D%5Bdir%5D=desc&start=0&length=100"
url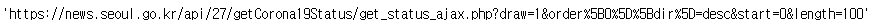
requests 라이브러리를 통해 데이터를 요청하여 반환받은 데이터 일부를 확인합니다.
import requests
response = requests.get(url)
data_json = response.json()
data_json
전체 페이지 데이터 요청(Requst)
앞서 말씀드렸다시피 서울시 최초 코로나 환자 발생 시점부터 가장 최근에 환자가 발생한 시점까지의 데이터가 필요하므로, 아래 이미지의 '확진자 현황 (10001번~현재)' 탭의 모든 페이지 데이터와 '확진자 현황 (1번~10000번)' 탭의 모든 페이지 데이터를 크롤링합니다.

먼저, 추가로 파이썬 time 라이브러리와 tqdm 라이브러리를 import 합니다.
- time: time.sleep()을 사용하여 한 개 페이지를 크롤링할 때마다 잠시 쉬면서 서버에 부담을 줄이기 위함입니다.
- tqdm: 데이터 사이즈가 클 때, for문의 진행 상태를 표시하기 위함입니다.
import time
from tqdm import trange
1) 일부 데이터 크롤링 테스트
전체 페이지를 크롤링하기 전에 일부 페이지 데이터를 크롤링하여 오류가 없는지 확인합니다. 처음부터 전체 페이지를 크롤링하면, 중간에 오류가 발생해도 발견하기 어렵기 때문입니다.
먼저, '확진자 현황 (10001번~현재)' 탭의 특정 페이지 데이터를 요청(request)하는 함수를 정의합니다.
# 1. '확진자 현황(10001번~현재)' 탭의 page_no 페이지에 존재하는 데이터 요청
def get_seoul_covid19_10001_current(page_no):
start_no = (page_no - 1) * 100
url = f"https://news.seoul.go.kr/api/27/getCorona19Status/get_status_ajax.php?draw={page_no}"
url = f"{url}&order%5B0%5D%5Bdir%5D=desc&start={start_no}&length=100"
response = requests.get(url)
data_json = response.json()
return data_json
# 2. '확진자 현황(1번 ~ 10000번)' 탭의 page_no 페이지에 존재하는 데이터 요청
def get_seoul_covid19_1_10000(page_no):
# 확진자 현황 (1번 ~ 10000번)의 최초 page_no를 확인해보면, '3'
start_no = (page_no - 3) * 100
url = f"https://news.seoul.go.kr/api/27/getCorona19Status/get_status_ajax_pre.php?draw={page_no}"
url = f"{url}&order%5B0%5D%5Bdir%5D=desc&start={start_no}&length=100"
response = requests.get(url)
data_json = response.json()
return data_json
이제 for문을 수행하면서 '확진자 현황 (10001번~현재)' 탭의 1~3 페이지 데이터를 크롤링합니다.
- tqdm 라이브러리 trange 모듈을 통해 for문 진행 상태를 확인할 수 있습니다.
- 최종 1~3페이지의 300개 데이터에 대한 오류가 없음을 확인할 수 있습니다.
- 참고로, 첫 번째 row의 날짜가 2021-01-31은 DB에 늦게 입력이 되었거나 날짜에 오타가 있는 것으로 추측됩니다.
page_list = []
all_page = 3
for page_no in trange(all_page + 1):
one_page_data_json = get_seoul_covid19_10000_current(page_no)
# 크롤링한 .json 타입 데이터에서 'data' key와 매칭하는 value 데이터를 데이터프레임으로 변환
one_page_df = pd.DataFrame(one_page_data_json["data"])
page_list.append(one_page_df)
time.sleep(0.5)
pd.concat(page_list)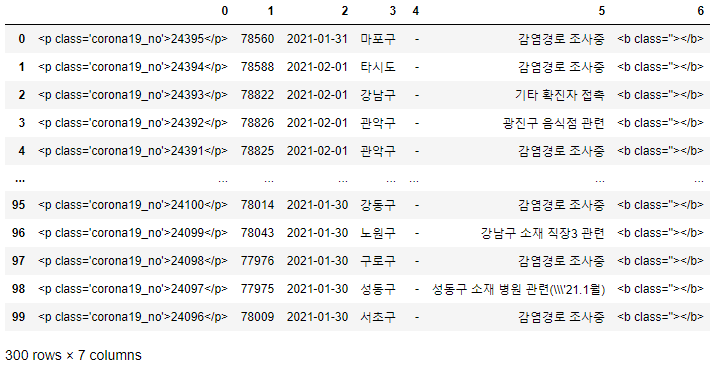
2) 최종 전체 데이터 크롤링
최종 각 '확진자 현황 (10001번~현재)' 및 '확진자 현황 (1번~10000번)' 탭의 전체 페이지에 존재하는 데이터를 크롤링합니다. 이를 위해 수행하는 함수를 각각 정의합니다.
# 1) '확진자 현황(10001번 ~ 현재)' 탭의 전체 페이지에 존재하는 데이터
def get_multi_page_list_10001_current(start_page, end_page=80):
page_list = []
for page_no in trage(start_page, end_page + 1):
one_page_data_json = get_seoul_covid19_10001_current(page_no)
if len(one_page_data_json["data"]) > 0:
one_page_df = pd.DataFrame(one_page_data_json["data"])
page_list.append(one_page_df)
time.sleep(0.5)
else:
return page_list
return page_list
# 2) '확진자 현황(1번 ~ 10000번)' 탭의 전체 페이지에 존재하는 데이터
def get_multi_page_list_1_10000(start_page, end_page=80):
page_list = []
for page_no in trange(start_page, end_page + 1):
one_page_data_json = get_seoul_covid19_1_10000(page_no)
if len(one_page_data_json["data"]) > 0:
one_page_df = pd.DataFrame(one_page_data_json["data"])
page_list.append(one_page_df)
time.sleep(0.5)
else:
return page_list
return page_list
이제 각 '확진자 현황 (10001번~현재)' 및 '확진자 현황 (1번~10000번)' 탭 전체 페이지 데이터에 대한 크롤링을 수행합니다.
# 1. '확진자 현황(10001번 ~ 현재)'
start_page = 1
end_page = 144
page_list = get_multi_page_list_10001_current(start_page, end_page)
df_all_10001_current = pd.concat(page_list)
# pd.read_html(url)로 읽어온 table[3]의 칼럼명 리스트로 변환하여 df_all_10001_current에 적용
df_all_10001_current.columns = table[3].columns.tolist()
df_all_10001_current.head()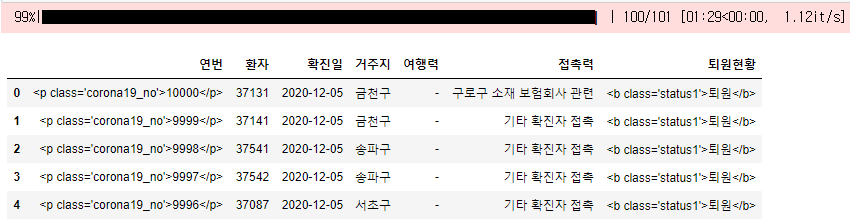
# 2. '확진자 현황(1번 ~ 10000번)'
start_page = 3
end_page = 103
page_list = get_multi_page_list_1_10000(start_page, end_page)
df_all_1_10000 = pd.DataFrame(page_list)
df_all_1_10000.columns = table[3].columns.tolist()
df_all_1_10000.head()
각 '확진자 현황 (10001번~현재)' 및 '확진자 현황 (1번~10000번)' 탭 전체 페이지 데이터를 한 개 데이터프레임으로 합칩니다.
- 최초 서울시 코로나 환자 발생 시점(2020-01-24) ~ 가장 최근 서울시 코로나 환자 발생 시점(2021-02-01)까지의 데이터를 모두 크롤링했습니다. (참고로, 첫 번째 row의 날짜가 2021-01-31은 DB에 늦게 입력이 되었거나 날짜에 오타가 있는 것으로 추측됩니다.)
df_all = pd.concat([df_all_10001_current, df_all_1_10000])
df_all
데이터 전처리
위 df_all 데이터프레임에서 "연번", "퇴원현황" 칼럼 데이터에서 HTML 코드를 제거하는 전처리를 수행합니다. 파이썬 re 라이브러리와 정규 표현식을 사용합니다. 먼저, re 라이브러리를 import 합니다.
import re
1) "연변" 데이터 전처리
"연번" 데이터는 가운데 숫자를 제외한 <p class='corona19_no'>, </p>를 제거해야 합니다. 이를 처리하는 함수를 정의합니다.
- "[^0-9]": 숫자가 아닌 모든 데이터
- 확신할 수는 없지만, num_string의 타입을 검사하는 이유는 혹시나 "연변" 데이터에 숫자만 포함되어 있는 경우를 대비한 것으로 추측됩니다. 데이터프레임 한 개 칼럼에는 여러 개의 데이터 타입(int, str, bool, ...)을 가진 데이터를 저장할 수 있기 때문입니다.
def extract_number(num_string):
if type(num_string) == str:
num_string = num_string.replace("corona19", "") # 'corona19'를 제거한 후에
num = re.sub("[^0-9]", "", num_string) # 숫자가 아닌 문자 모두 제거
num = int(num)
return num
else:
return num_string이제 "연변" 칼럼 데이터를 한 개씩 extract_number() 함수에 입력하여 전처리를 수행합니다.
- HTML 코드가 제거되고, 번호만 남은 것을 확인할 수 있습니다.
df_all["연번"] = df_all["연번"].map(etract_number)
df_all
2) "퇴원현황" 전처리
"퇴원현황" 데이터는 '퇴원' 또는 '사망'을 제외한 <b class=..>, </b>를 제거해야 합니다. 이를 처리하는 함수를 정의합니다.
- "[^가-힣]": 한글이 아닌 모든 데이터
def extract_hangeul(origin_text):
subtract_text = re.sub("[^가-힣]", "", origin_text) # 한글이 아닌 문자 제거
return subract_text
이제 "퇴원현황" 칼럼 데이터를 한 개씩 extract_hangeul() 함수에 입력하고, 퇴원도 사망도 아닌 환자에 대하여 Nan을 저장하는 전처리를 수행합니다.
df_all["퇴원현황"] = df_all["퇴원현황"].map(extract_hangeul)
df_all.loc[df_all["퇴원현황"].isin(['']), "퇴원현황"] = np.nan
df_all
최종 데이터프레임 저장
최종 df_all 데이터프레임을 .csv 파일로 저장합니다. 파일명에는 가장 최근에 환자가 발생한 날짜로 지정합니다.
- .to_csv()은 기본적으로 'utf-8' 인코딩 방식으로 저장합니다.
- 만약 저장한 .csv 파일을 Excel로 실행하여 한글을 보려면, 'cp949' 인코딩 방식으로 저장해야 합니다.
- 하지만, 보통 .csv 파일을 직접 실행하지 않으므로, 'utf-8' 형식으로 저장합니다.
date = '2021_02_01'
file_name = f"seoul-covid19-{date}.csv"
df_all.to_csv(f"data/{file_name}", index=False)
마무리
지금까지 지금까지 서울시에서 제공하는 서울 코로나 확진자 현황 데이터를 크롤링하는 과정에 대하여 정리하였습니다. 데이터를 분석하기 위해서는 이전에 수집하는 단계가 필요한데, 이번 포스팅이 누군가에게 도움이 되셨으면 좋겠습니다 :)
다음 포스팅에서는 본격적으로 크롤링한 데이터를 다양하게 분석한 내용에 대하여 정리해보겠습니다.
감사합니다!
'데이터 분석 > Python' 카테고리의 다른 글
| 파이썬 서울시 코로나19 현황 분석하기 - 2. EDA(Exploratory Data Analysis) (0) | 2021.02.08 |
|---|
